Linking local Ollama with Home Assistant
Easy integration of Ollama running on Mac with Home Assistant

As I try and find the time to publish all of the lingering drafts I have stored on my personal Notion for this blog, I will start by publishing a small thing I found pretty useful: integrating a local LLM to give me concise info from Home Assistant.
Home Assistant just announced the tools API support for Ollama in their 2024.8 release notes. My Mac Studio is already running Ollama at home for enhancing Raycast, Apple Notes, Obsidian etc.
I currently use the OpenAI integration with Home Assistant to tailor notifications but want to avoid paying API usage costs (even if they're small) and want to try and take the local route and see how that goes. I have a beefy machine at home capable of running AI/LLM so why not try?
I found that there were some small steps involved in getting it up and running. Here's those steps so you can replicate it at home.
Prerequisites
- Home Assistant 2024.8
- A macOS machine with an Apple ARM ("M Series") chip. These ARM chips run LLMs significantly faster than trying it out on an x64 machine. (I use my new Mac Studio)
- Ollama installed (I did this with homebrew)
Prepping Ollama
In order for other devices on my network (my Home Assistant VM) to be able to send requests to my Mac Mini I had to explicitly set the Ollama host to 0.0.0.0 instead of just localhost (127.0.0.1)
Here's a small snippet with all CLI commands you need so you can move along to integrate it with HA:
$ brew install ollama
$ ollama pull llama3.1
$ launchctl setenv OLLAMA_HOST 0.0.0.0:11434
$ brew services restart ollamaThen open a browser and confirm that if you navigate to the local IP address of your Mac (e.g 192.168.1.x:11434) it shows Ollama is running
Connecting HA
Add Ollama from the Devices & Integrations page and enter the LAN IP from your Mac:
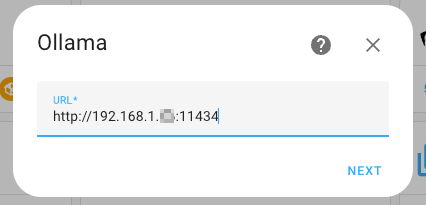
And choose the correct model. In this case we downloaded llama3.1 (latest Meta LLM). After it's been set up correctly you can use the conversation.process Action (previously called Services in HA) to interact with Ollama:
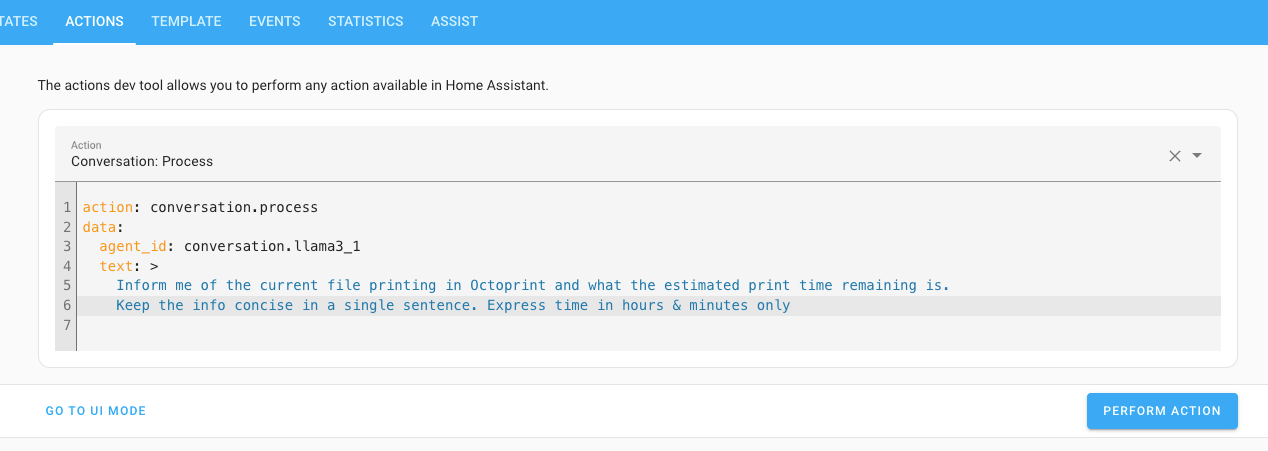
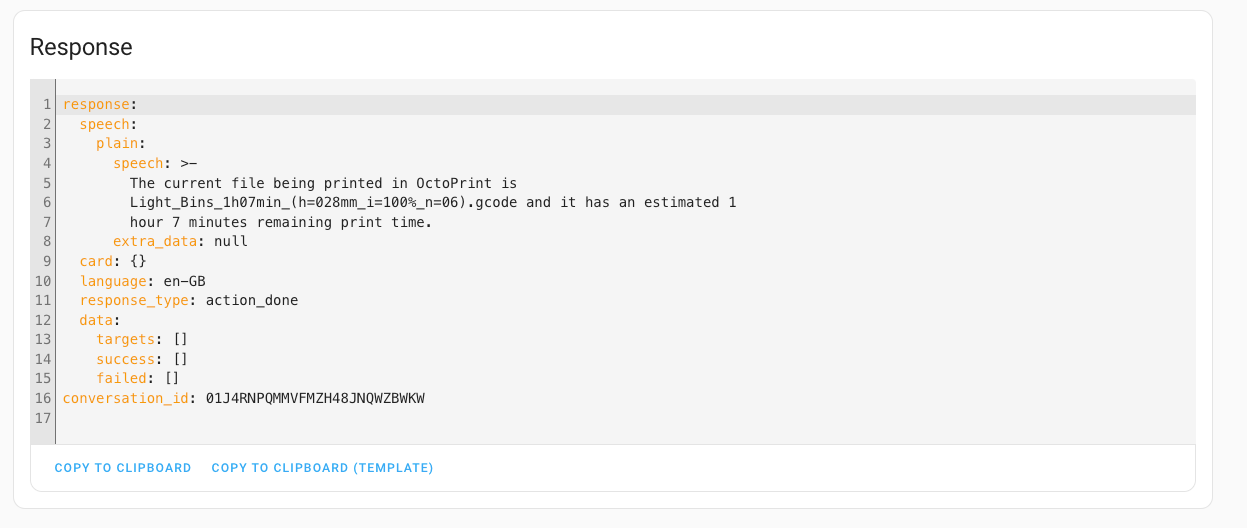
Voila! You could take this a bit further by including the conversation.process action inside your scripts & automations, e.g sending out a notification or voice message across the house.
Takeaways
- Plugging in local LLM via Ollama is fairly easy using homebrew
- You do need an Mac ARM chip for this, and even then there's a few seconds daily where OpenAI is instant. Trying to work around this.
- Depending on the amount of concurrent request Ollama will handle (e.g Raycast + Home Assistant) you could see a significant performance hit on MEM on your Ollama server (Mac Studio in this case)